Flyway是什么
随着项目CICD接入,一键启动,敏捷开发已经成为降本提效的不二法宝,其中涉及SQL的变更还不够智能和自动化,因此亟需一款工具能够帮助开发及运维人员高效简便地完成SQL变更,Flyway正是可以满足我们需求的一款工具。
当我们打开Flyway的官网,在首页可以看到关于Flyway的一段英文介绍:

Flyway是数据库的版本控制,跨所有环境的稳健架构演变。轻松、愉快和简单的SQL。

总的来说,Flyway是一款专为CI/CD打造的,能对数据库变更做版本控制的工具。
Flyway支持的数据库很多,主流的数据库都能够完美支持,官网摘抄如下:
Supported databases are Oracle, SQL Server (including Amazon RDS and Azure SQL Database), Azure Synapse
(Formerly Data Warehouse), DB2, MySQL (including Amazon RDS, Azure Database & Google Cloud SQL), Aurora MySQL,
MariaDB, Percona XtraDB Cluster, TestContainers, PostgreSQL (including Amazon RDS, Azure Database, Google Cloud
SQL, TimescaleDB, YugabyteDB & Heroku), Aurora PostgreSQL, Redshift, CockroachDB, SAP HANA, Sybase ASE,
Informix, H2, HSQLDB, Derby, Snowflake, SQLite and Firebird.
Flyway解决的问题
在项目或产品研发过程中,很难一开始就把业务理清楚,把代码逻辑和数据库表设计好,因此代码和数据表也会在迭代周期内不断迭代。我们都习惯使用SVN或者Git来对代码进行版本管理,主要是为了解决多人开发代码冲突和版本回退的问题。
其实,数据库的变更也需要版本控制,在日常开发和环境部署中,我们经常会遇到下面的问题:
在开发环境部署程序发现报错,定位是自己写的SQL脚本忘了在当前环境执行导致;
从Git上新down下来的代码运行报错,定位发现是其他同事修改了的SQL脚本没有在当前环境执行导致;
每次发布包都需要发布SQL文件包和应用程序的版本包;
线上环境部署报错,发现是运维没有按照你投产文档里面说明的SQL脚本执行顺序操作执行导致;
流水线可以自动化部署程序,但是SQL脚本还是需要手动执行或者流水线执行SQL脚本配置比较繁琐;
其他场景....
有了Flyway,这些问题都可以轻松的解决。Flyway可以对数据库进行版本管理,可以自动执行SQL,能快速有效地用于迭代数据库表结构,并保证部署到测试环境或生产环境时,数据表都是保持一致的;
Flyway主要工作流程
Flyway工作流程如下:

1、项目启动,应用程序完成数据库连接池的建立后,Flyway自动运行。
2、初次使用时,Flyway会创建一个flyway_schema_history表,用于记录sql执行记录。
3、Flyway会扫描项目指定路径下(默认是classpath:db/migration)的所有sql脚本,与flyway_schema_history表脚本记录进行比对。如果数据库记录执行过的脚本记录,与项目中的sql脚本不一致,Flyway会报错并停止项目执行。
4、如果校验通过,则根据表中的sql记录最大版本号,忽略所有版本号不大于该版本的脚本。再按照版本号从小到大,逐个执行其余脚本。
##在SpringBoot项目使用Flyway
Flyway既支持使用客户端command-lineclient命令行方式也支持JAVA API方式升级数据库,本文只介绍JAVA API以Maven引入插件方式的使用,更多方式可以查看官网;
引入依赖
在start.spring.io上新建一个SpringBoot工程,引入数据库驱动依赖等,同时引入Flyway的依赖,这个步骤比较简单,不做过多说明(本文示例使用的是Mysql数据库);
<dependency> <groupId>org.flywaydb</groupId> <artifactId>flyway-core</artifactId> <version>7.14.0</version><!-- 截至发稿前,官网最新版本是7.14.0 --> </dependency>
添加Flyway配置
spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/xukj_flyway?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT username: flyway password: xxx flyway: # 是否启用flyway enabled: true # 编码格式,默认UTF-8 encoding: UTF-8 # 迁移sql脚本文件存放路径,默认db/migration locations: classpath:db/migration # 迁移sql脚本文件名称的前缀,默认V sql-migration-prefix: V # 迁移sql脚本文件名称的分隔符,默认2个下划线__ sql-migration-separator: __ # 迁移sql脚本文件名称的后缀 sql-migration-suffixes: .sql # 迁移时是否进行校验,默认true validate-on-migrate: true # 当迁移发现数据库非空且存在没有元数据的表时,自动执行基准迁移,新建schema_version表 baseline-on-migrate: true
创建SQL脚本
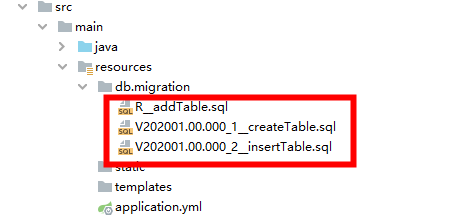
项目创建以后,在src/resources下有 db/migration(或db.migration)目录,在其中创建对应的SQL文件,基于约定由于配置的原则,不同的类型通过文件命名方式进行区分

Flyway对数据库的所有更改都称为迁移;版本迁移(Versioned Migrations)以V开头,只会执行一次;回退迁移(Undo Migrations)以U开头,执行一旦发生破坏性更改,就会很麻烦,项目中一般不用;可重复执行迁移(Repeatable Migrations)以R开头,每次修改后都会重新执行。
总结如下:
仅需要被执行一次的SQL命名以大写的"V"开头,后面跟上"0~9"数字的组合,数字之间可以用“.”或者下划线"_"分割开,然后再以两个下划线分割,其后跟文件名称,最后以.sql结尾。比如,V2020.00.000_1create_table.sql,V202001.00.000_2insertTable.sql,V2.1.5__create_table.sql。
可重复运行的SQL,则以大写的“R”开头,后面再以两个下划线分割,其后跟文件名称,最后以.sql结尾。比如,RaddTable.sql,Rupdate_user.sql。
版本号需要唯一,否则Flyway执行会报错;如果V__脚本.sql,已经执行过了,不能修改里面的内容,再次执行Flyway就会报错。R——脚本.sql,如有变化可以执行多次。
V开头的SQL执行优先级要比R开头的SQL优先级高。
如下,我们准备了三个脚本,分别为:
1、V2020.00.000_1__create_table.sql,代码如下,目的是创建一张表,且只执行一次
CREATE TABLE `test_flyway_table` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键', `time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、V202001.00.000_2__insertTable.sql,代码如下,目的是往表中插入一条数据,且只执行一次
INSERT INTO `test_flyway_table` VALUES ('1', '2021-06-28 17:48:48');
3、R__addTable.sql,代码如下,目的是每次启动如果有变化,则执行一次
update `test_flyway_table` set time = '2021-08-23 17:48:48' where id =1;
对应目录截图如下:
运行
按照上面配置完成,已经足够我们开始运行了,此时,我们第一次启动项目,如果配置没有错误,运行截图如下:
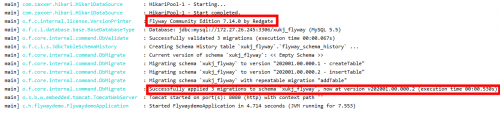
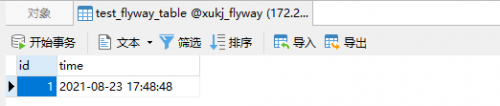
此时,我们刷新数据库,可以看到Flyway的历史记录表已经生成并插入了三个版本的记录:

而且,表也已经创建好了并有一条数据:
此时不做任何改变,重启程序,日志如下:
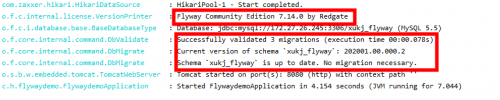
日志显示表没有变化,不做变更,查看两张表的内容也无变化。
如果我们修改V202001.00.000_2__insertTable.sql脚本,重启程序,就会报错,提示信息如下:
Caused by: org.flywaydb.core.api.exception.FlywayValidateException: Validate failed: Migrations have failed validation Migration checksum mismatch for migration version 202001.00.000.2 -> Applied to database : 1190158040 -> Resolved locally: 843339817. Either revert the changes to the migration, or run repair to update the schema history.
如果我们修改R__addTable.sql脚本,重启程序,脚本会再次执行,并且Flyway的历史记录表也会增加本次执行的记录。
Flyway的执行效率
为了验证Flyway项目数据库迭代了较久时间,积累了几百个Sql以后是否会拖慢项目的启动速度?进行了一个对照组试验:
| 场景(sql文件控制在10K以内) | 执行平均时长(单位:秒) |
|---|---|
| 放1个已经被执行过的SQL脚本,反复启动项目 | 11.1 |
| 放25个已经被执行过的SQL脚本,反复启动项目 | 11.4 |
| 放50个已经被执行过的SQL脚本,反复启动项目 | 11.6 |
| 放100个已经被执行过的SQL脚本,反复启动项目 | 12.19 |
脚本在历史记录表中有记录,即使有几百条SQL脚本,每次项目启动只执行单次迭代的脚本,所以耗时主要来源于两个方面:
Flyway依次读取脚本中内容时的IO开销;
Flyway计算脚本checksum值的算法开销;
对于IO开销而言,每个脚本如果不是涉及大量的数据变更,只是表结构的变更,脚本的大小都非常小,可以不考虑.事实上Flyway也不适合大量的数据变更时使用,因此IO开销对启动耗时的增量基本可以忽略
| 场景 | 执行平均时长(单位:毫秒) |
|---|---|
| 读取一个超大文件,约1M,并进行计算,反复执行多次 | 48 |
| 读取一个正常大小的SQL脚本,约10K,并进行计算,反复执行多次 | 4 |
由此可见,即便是有上百个正常大小的sql,计算checksum值也不会耗费太多的时间,基本都可以在1秒内完成,所以接入Flyway后也不必担心会有历史包袱。